




Call me biased, but Analytics Engineering, powered with tools like dbt, is one of the best data careers today and it is only going to increase in value as companies move to modern data stacks. Analytics engineering roles are empowering, fun, lucrative, and have high-growth potential and jobs are within reach for people with a variety of data or engineering backgrounds. Personally, dbt empowered me to take ownership of the data I was working with. It allowed me to move fast without running into blockers on deploying new data models or changing existing ones. It helped me solidify my understanding of software engineering best practices around version control, modularity, code review, and collaboration. dbt was the first step for me in getting into data infrastructure work. It has allowed many analysts like me to jumpstart their careers.
I believe that with the right set of tools and a little training – more on that in a bit :) – anyone can break into the analytics engineering field. My personal journey started when I was working as a business analyst at Wayfair, the world’s largest e-commerce furniture company. I was learning a ton there and gaining experience working with tools like Git, SQL, and Tableau. At the time, I was also getting a master’s degree in business analytics. I knew that in the long-term I wanted to pursue a career path that was more technical, with more opportunities to learn and grow. That knowledge set me on my path to a career in analytics engineering.
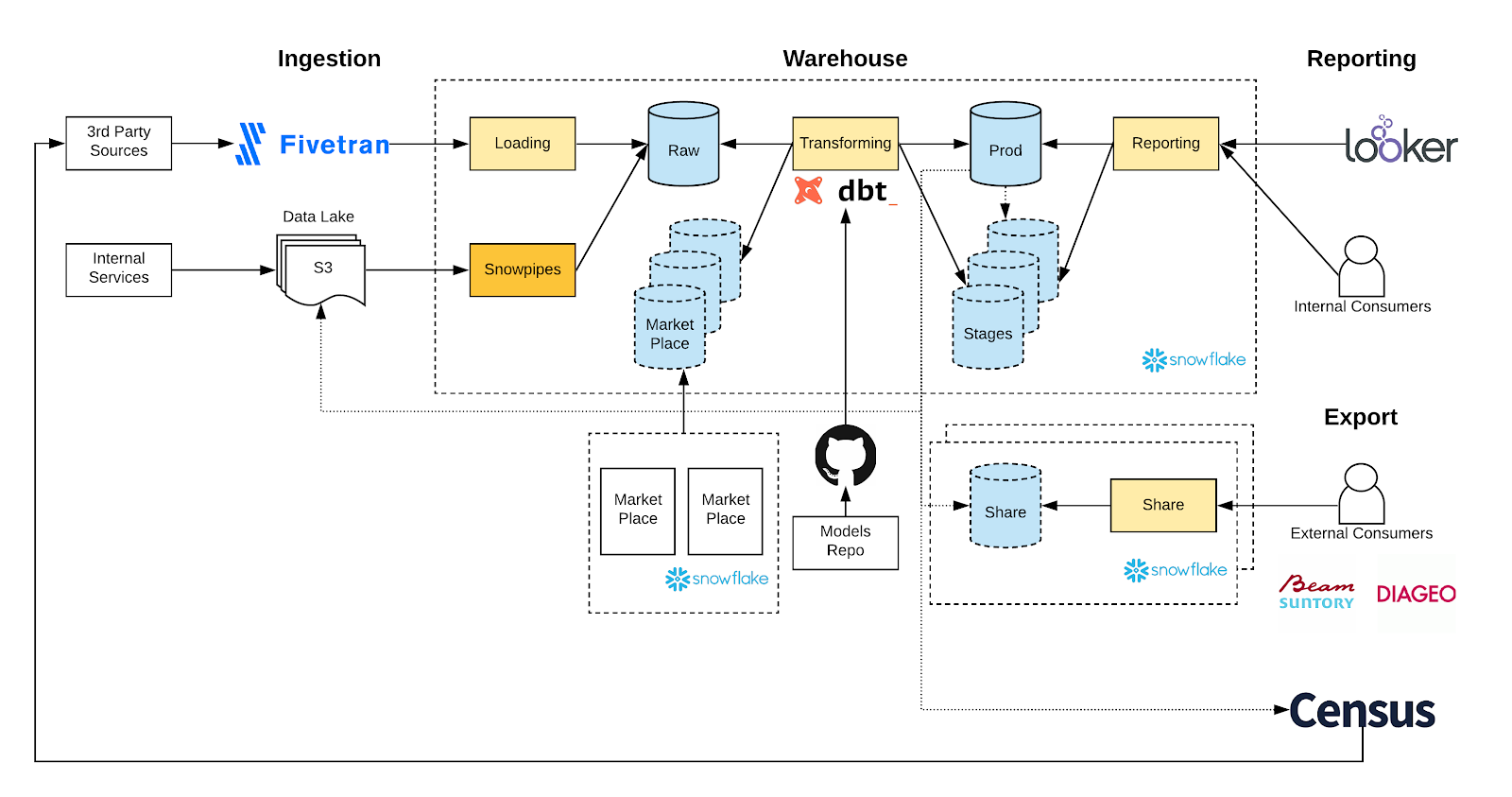
In early 2019, I started job hunting in the analytics engineering space. I soon landed a position as a business intelligence (BI) analyst at Drizly, a company that delivers alcohol to your doorstep and was pretty popular over the last few years! I was very lucky to find myself at Drizly, empowered by an amazing mentor and boss to tackle big challenges, and I still feel lucky to be there. The last few years at Drizly have been fueled by immense growth, and we were acquired by Uber in the fall of 2021. As an early member of the data team, I got to build vital data infrastructure from scratch, using modern data stack tooling like dbt, Fivetran, and Snowflake. Being part of such a new team was an amazing opportunity to learn all that I could about analytics engineering and data infrastructure. Every day, I faced the challenge of solving tough technical problems, and I grew quickly as an engineer because of it.
Since starting at Drizly three years ago, I’ve been promoted to a Data Engineering Manager and I'm starting to build our Data Platform team. I’ve created this dbt course with Uplimit so that I can help other people break into analytics engineering by sharing what I’ve learned, and by bringing in Analytics Engineering all-stars to share their hard-earned lessons too.
The Value of Learning on the Job
My position at Drizly was a lot more technical than my prior role b at Wayfair, so when I started, there was definitely a lot to learn. At Drizly, I had to be a self-starter, seeking out knowledge about tools that I (and others on the team) hadn’t worked with.
I learned a lot of the technical aspects and best practices of dbt by interacting with the dbt community. The community has its own Slack channel, which is a great place to ask questions and learn more about how to best use the tool. People in the channel are supportive and quick to provide helpful responses and advice.
Building Drizly’s data infrastructure from scratch presented our BI team with a lot of exciting challenges. We learned by examining what other people were doing – we’d explore open source documentation from Gitlab and other dbt users, we’d review the dbt documentation for best practices, and we’d ask tons of questions. We also shared our own work back with the community as well. Pretty early on in our journey working with dbt and Snowflake, we developed a way to use dbt to automate data sharing in Snowflake. Since then, we’ve continued to share the projects we work on. Modern data stack development is still in its early stages, so people are always interested in seeing how we integrate the tools in our technology stack.
Even with all our planning, we obviously didn’t get everything right the first time – no one ever does! Development is an interactive process, and our data infrastructure has gone through several phases of general improvements. Every time we try something new, we learn more about what works and what doesn’t. That ongoing learning process is part of what makes analytics engineering so rewarding.
Building the course I wish I had
When designing this course, it was important to me that I bring in my own experience. I wanted to ensure that learners would gain practical knowledge of how to use dbt in the real world. I modeled the course after real-life projects, so that learners could experience the complete process of building a dbt project from scratch. We created a synthetic data set for a fictional e-commerce company called Greenery that sells houseplants. I start the course by setting the scene for our students and their job of the next four weeks:

Since I wanted the course to be as close to the real world as possible, I designed the course to focus on the types of problems that you’d face when working for an actual company. For example, we start off the course by discussing how to properly set up a dbt project. We then explore other tasks that you might encounter in a real job, like manipulating tables in a database, using dbt macros to create reusable functions, and dealing with stale data. We also spend time thinking about different ways to model data to answer business questions from stakeholders like “where are people falling out of our conversion funnel?” Several questions in the projects are real questions often get asked at work.
Throughout the course I share how we’ve built our data stack at Drizly (example below) and our approaches to testing, data modeling, etc, but students also hear different approaches from instructor Jake Hannan from Gopuff, TA Ekaterina Khrushch from Contentful, and more. We bring in experts in different topics: Miles Russell from GitLab does a deep dive on data modeling for the modern data stack, while Niall Woodward, creator of some of the most widely used packages in the dbt community, teaches macros and packages in week 3 of the course.
To build out the course experience even further, we bring in guest speakers who are really successful in the data space. Some of our guest speakers include Jason Ganz from dbt labs who is close to many organizations adopting dbt, Emilie Schario, an important analytics engineering pioneer at GitLab and thought leader, Taylor A Murphy, PhD, head of Product and Data at Meltano, and Erika Pullum, who moved into analytics engineering from a process engineering background, giving her an exciting perspective on analytics.
A Vibrant Course Community
The people in the course learn from me, of course, but I’ve learned a lot from them as well. People think about problems in a variety of ways, and it’s fascinating to see the different ways people apply concepts to their work. Because the cohort is made up of people from diverse backgrounds, we’re always encountering new perspectives and ideas.
We’ve had data engineers and analytics engineers who wanted to get stronger at their craft, software engineers who want to get into data/analytics, and many data analysts or business analysts who want to be more self-sufficient and explore analytics engineering.
We had students from larger companies like Slack, Electronic Arts, and Amplitude, with others from government, and nonprofits.
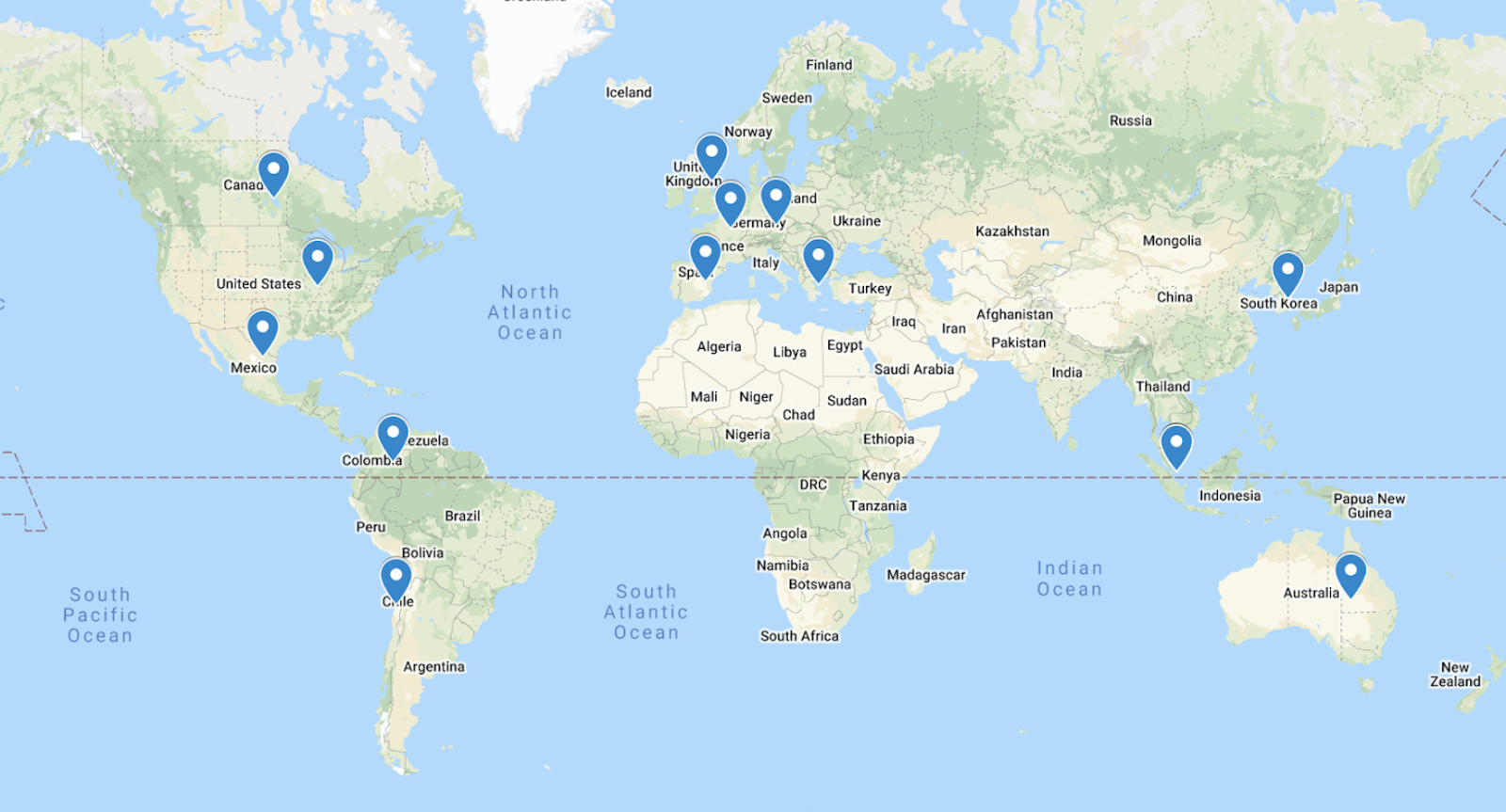
We are a truly global classroom too – our last cohort of ~80 students came from 5 continents and 9 time zones. We had students from Mexico, UK, Singapore, Chile, South Korea and more.
There’s a real sense of community in the course, and our Slack workspace gets a ton of interaction! People in the cohort are always willing to answer questions or help someone out. Even people from past cohorts sometimes pop in to weigh in on questions or give advice. People often ask questions that aren’t directly related to the course, such as how a certain concept could be applied within their company. Jake Hannan and I often chime in with how we do things at Gopuff or Drizly, but other learners will also help out by volunteering their own perspectives. Learners encourage each other to persist (see below), especially when jobs and responsibilities get busy.
The best part of teaching this course is getting to see people get new jobs or move into new roles using dbt. It’s especially great to see people move into analytics engineering from entirely different fields – changing industries can be a daunting prospect, so I love that this course makes it possible for them to do that! We help each other in our roles and celebrate when students make career leaps!
If you want to learn about dbt and gain the skills to launch a career in analytics engineering, you can enroll in the course here.